
The Cost of Intelligence: Benchmarking Claude 4.5 vs. GPT-5 for High-Volume Data Pipelines Benchmarking
The definitive 2026 LLM cost-performance guide. Discover the 'Cost-per-Correct-Answer' (CPCA) for Claude 4.5 and GPT-5 in enterprise data pipelines.

Algorithmic Trading with LLM Sentiment: Building a Real-Time News Pipeline in Python Data Science
Master sentiment-driven trading in 2026. Learn how to build a Python pipeline that converts global news into actionable alpha signals using DeBERTa and CCXT.

AI-Powered Web Scraping: Combining Playwright, LLMs, and Python for Structured Data Advanced
Master AI web scraping in 2026. Learn how to build self-healing pipelines that combine the speed of Playwright with the intelligence of LLMs.
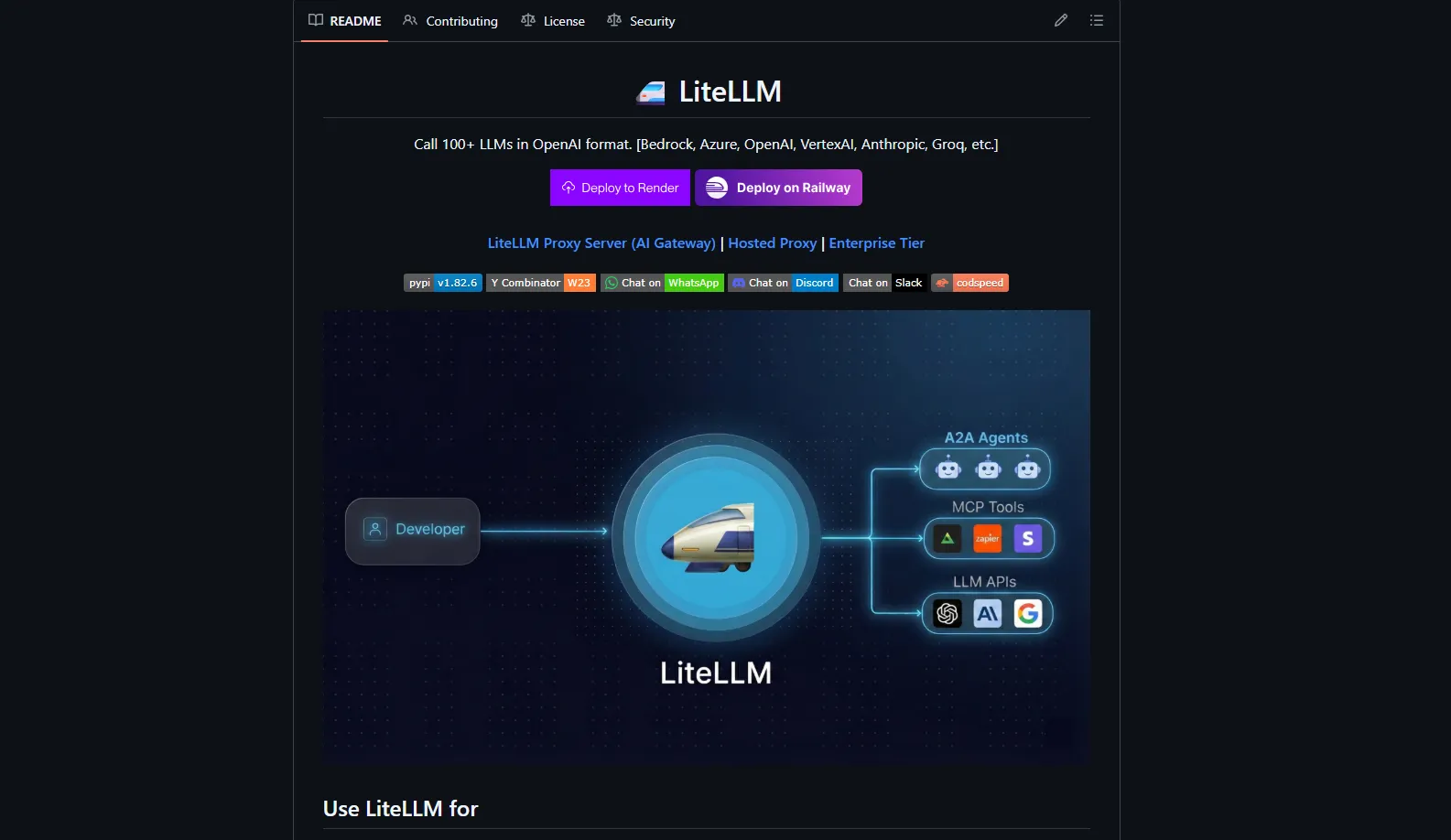
LiteLLM: The Ultimate Open-Source AI Gateway for 100+ LLMs Guide
Learn how LiteLLM unifies 100+ LLMs (OpenAI, Anthropic, Gemini, Groq) behind one AI gateway, cuts provider lock-in, and gives teams full control, observability, and cost tracking.